日本語も対応した学習済み単語ベクトルのFastTextをFacebookが公開しています。 これをColabolatoryで使ってみて以下のような、類似単語の分布を描いてみます。
Colaboratoryを使います。 Google Driveにあげたデータを利用することが簡単になってました。 Colabでいっぱい試して、大きな分析はサーバやローカルで分析するのがよさそうですね。
単語ベクトルの学習済みモデルを利用する
fastTextの日本語の学習済み単語ベクトルを利用します。 モデルにはいくつか種類がありますが、今回はこちらにあるWEBクローラーとWikipediaの文書から学習したモデルを利用します。
この中の日本語のファイルcc.ja.300.vec.gz(1.2GB)をダウンロードして、Google Driveにアップロードしておきます。
新規のColabolatoryを開いてGoogle Driveをマウントします。
fastTextのライブラリを利用する手もありますが、ここでは自然言語処理に便利なライブラリのgensimに任せてみます。 マウント出来たらドライブを開いて、先ほどアップロードしたモデルのパスをgensimに渡してロードします。 ロードには10分くらいかかるので気長に待ちましょう。
import gensim
# 学習済モデルのパス
model_path = '/content/drive/MyDrive/Colab Notebooks/fasttextmodel/cc.ja.300.vec.gz'
# ロードに10分くらいかかる
model = gensim.models.KeyedVectors.load_word2vec_format(model_path, binary=False)
モデルの形式を確認します。 このモデルは長さ5のn-gramからCBOWで学習しています。 ひとつの単語は300次元のベクトルで表される。
# 登録している単語の数
print(len(model.vocab.keys())) # 2000000
# ひとつの単語ベクトルの次元
model['猫'].shape # (300,)
Colaboratoryではコードブロックの最後の行のオブジェクトはprintみたいに結果を出力できます。
単語ベクトルを試す
単語ベクトルが扱えるようになったので色々と遊んでみる。 読み込んだ単語ベクトルで出来ることはこちらで紹介されています。
What can I do with word vectors?
補足ですが、fastTextから読み込んだのは、full modelではなくKeyedVectorsです。主な違いはKeyedVectorsはこれ以上トレーニングできない代わりに、トレーニングに必要な内部データ構造を排除して軽量にしています。 また、fastTextはfull modelとしてロードできないそうです。
Why use KeyedVectors instead of a full model?
類似する単語を挙げる
指定した単語に類似した単語を挙げてみます。 類似した単語と単語のユークリッド距離が出ます。
from pprint import pprint
pprint(model.most_similar('猫', topn=10))
[('ネコ', 0.8059155941009521),
('ねこ', 0.7272598147392273),
('子猫', 0.720253586769104),
('仔猫', 0.7062687873840332),
('ニャンコ', 0.7058036923408508),
('野良猫', 0.7030349969863892),
('犬', 0.6505385041236877),
('ミケ', 0.6356303691864014),
('野良ねこ', 0.6340526342391968),
('飼猫', 0.6265145540237427)]単語の類似度を出す
print(model.similarity('猫', '犬'))
print(model.similarity('猫', '人'))
0.65053856
0.23371725猫は人より犬に近いようですね。
王様 - 男 + 女 = ?
# 単語ベクトルの演算
new_vec = model['王様'] - model['男'] + model['女']
# 計算したベクトルに類似した単語
pprint(model.similar_by_vector(new_vec))
[('王様', 0.8916897773742676),
('女王', 0.527921199798584),
('ラジオキッズ', 0.5255386829376221),
('王さま', 0.5226017236709595),
('王妃', 0.5000214576721191),
('裸', 0.487439900636673),
('タプチム', 0.4832267761230469),
('アンナ・レオノーウェンズ', 0.4807651937007904),
('ゲムケン', 0.48058977723121643),
('お姫様', 0.4792743921279907)]よくある単語の関係を計算するやつを試してみます。
単語はベクトルですので計算ができます。
トップが王様で、次いで予測していた女王が出てきました。
この結果のようなタプチムやゲムケンなど聞きなれない言葉や、中国語も混じっていたりします。
利用しているfastTextのモデルはWikipediaとWEBクローラーで集めたの文書で学習しています。
精度が悪いものは、おそらく、その単語の学習データ少なかったのでしょう。
単語はベクトルの計算は以下のようにも書けます。 こちらの結果は言葉の感覚的にあってました。
model.most_similar(positive=['姪', '男性'], negative=['女性'])
[('甥', 0.8209505081176758),
('叔父', 0.6412274837493896),
('叔母', 0.6293267011642456),
('従姉', 0.6224151849746704),
('弟', 0.6069883108139038),
('従兄', 0.595562756061554),
('従姉妹', 0.594235360622406),
('伯父', 0.5939351916313171),
('義妹', 0.5894800424575806),
('従兄弟', 0.5876302719116211)]単語の類似度を出す
print(model.similarity('猫', '犬'))
print(model.similarity('猫', '人'))
0.65053856
0.23371725単語の類似度の分布をグラフにする
ここから趣向を変えて、単語の類似度をグラフに表してみます。
いくつかの単語にそれぞれ類似した単語をクラスターとして、どんな分布になっているか散布図にプロットしていみる。
import numpy as np
# 入力した単語に類似した単語とベクトルを返す
def similars(words, model):
vectors = []
cluster = []
label = []
for i in range(len(words)):
word = words[i]
similar = model.similar_by_word(word, topn=10)
for x in similar:
cluster.append(i)
label.append(word)
vectors.append(model[x[0]])
return vectors, cluster, label
words = ['猫', '銃', '鉄', '病原菌']
vectors, cluster, label = similars(words, model)
# ベクトルの次元を確認
print(np.array(words).shape)
print(np.array(cluster).shape)
print(np.array(vectors).shape)
# 類似した単語の確認
for word in words:
similar = model.similar_by_word(word, topn=10)
print(word, [x[0] for x in similar])
鉄の単語だけバグってますね。中国語でしょうか?
(4,)
(40,)
(40, 300)
猫 ['ネコ', 'ねこ', '子猫', '仔猫', 'ニャンコ', '野良猫', '犬', 'ミケ', '野良ねこ', '飼猫']
銃 ['拳銃', '銃器', '短銃', '小銃', 'ダルヌ', '猟銃', 'アサルトライフル', '散弾', 'レムリカ', '蟲砕']
鉄 ['拐仙', '蕉館', '勒諸', 'ワン・アンダードッグ', '拐山', 'ブリキンガー', '珪輝', '拐李', 'ぱいぷ', '鋼鉄']
病原菌 ['病原', '細菌', 'ウイルス', 'ばい菌', 'エボラウィルス', '伝染病', '感染', '菌', 'ウィルス', 'ゾンビウィルス']グラフに日本語描画する際には▼をインストールしておくと勝手に日本語に対応してくれる。これがないと□□□□□と豆腐になる。ありがたい!
!pip install japanize-matplotlib
▼ベクトルは300次元のままだと表すことができないため、主成分分析(PCA)で2次元まで次元を減らします。 あとは、クラスター毎に色を付けて散布図にプロットしています。
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import japanize_matplotlib
def draw_scatter_plot(vectors, words, cluster):
colors = ["b", "g", "r", "c", "m", "y", "k"]
# Scikit-learnのPCAでn_componentsの数値で次元数を決める
pca = PCA(n_components=2)
coords = pca.fit_transform(vectors)
# matplotlibによる可視化
fig, ax = plt.subplots()
x = [v[0] for v in coords]
y = [v[1] for v in coords]
for i in range(len(words)):
xx = []
yy = []
for c, a, b in zip(cluster, x, y):
if i == c:
xx.append(a)
yy.append(b)
ax.scatter(xx, yy, c=colors[i % 7], label=words[i])
ax.legend(loc='upper right')
plt.show()
draw_scatter_plot(vectors, words, cluster)
出力
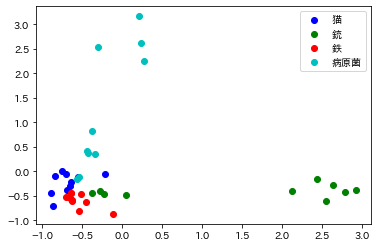
視覚的にわかりやすいグラフになりました。
鉄と銃のクラスターよりも、鉄と猫のクラスターのほうが近く固まっていたのは、鉄の単語がうまく学習できていなかったからかと思います。
単語を変えて遊べるので試してみてください。