以前にML-Agentsの環境を作りプリセットのサンプルで遊びました。 今回は自分で学習環境を作成してみます。
Making a New Learning Environment - ML-Agents Release 12 このドキュメントに従って新しく作っていきます。
作るのはボールがターゲットに向けて転がるゲームです。

環境
- Unity 2019.4
- Python 3.6.4 (Anaconda 4.9.2)
- ML-Agents Release 12
- mlagents 0.23.0 (pip Package)
- com.unity.ml-agents 1.7.2-preview (Unity Package)
こちらに環境の作り方を書きました。 環境を作っていてサンプルの学習が実行できていることを前提とします。
また、v1.1とは構成やソースコードが異なっているようです。バージョンアップで変わることもあるので、この記事は参考程度に見てください。
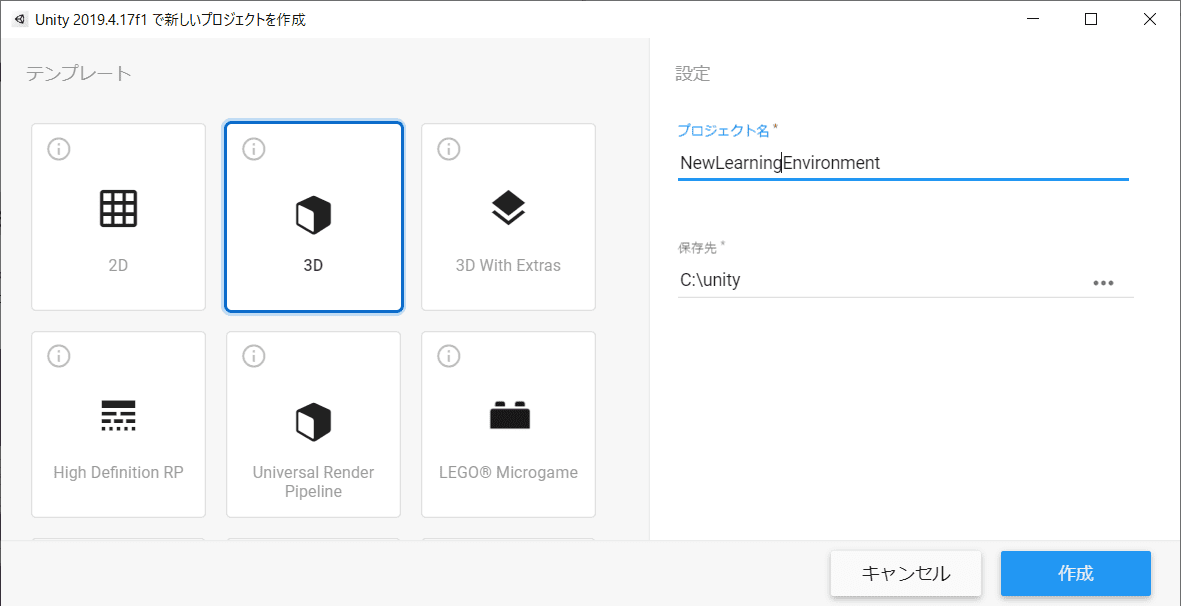
プロジェクトを作成する
Unity Hubから新規でプロジェクトを作成するところから始めます。
テンプレートは3Dとします。
ML-Agentsのパッケージを追加する
※ 事前にML-Agents Release 12 - GitHubからソースをダウンロードして下さい。
メニューの「Window」から「Pakage Manager」を開きます。
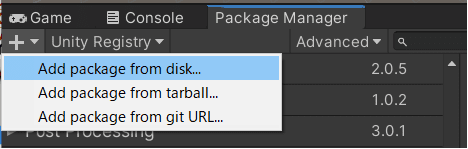
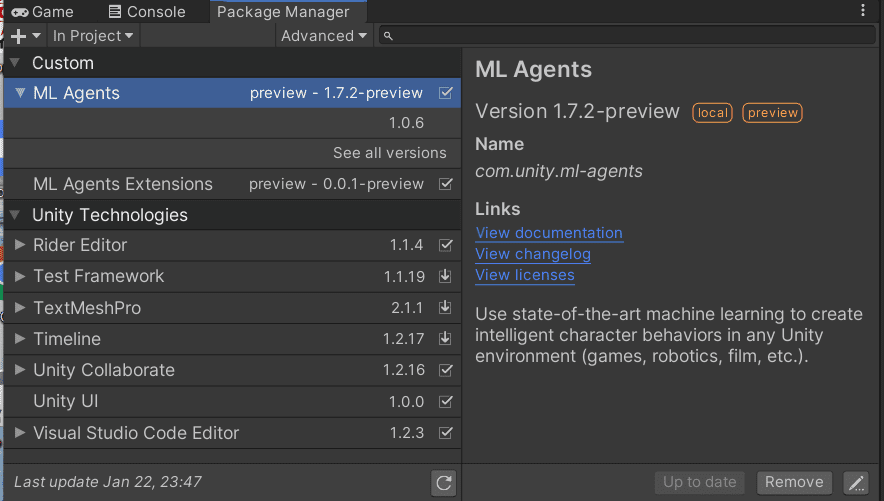
「Add package from disk..」を選んでダウンロードしてきたml-agentsのフォルダから.\ml-agents\com.unity.ml-agents\package.jsonを開いてパッケージをインポートします。
同様に拡張パックの.\ml-agents\com.unity.ml-agents.extensions\package.jsonもインポートします。
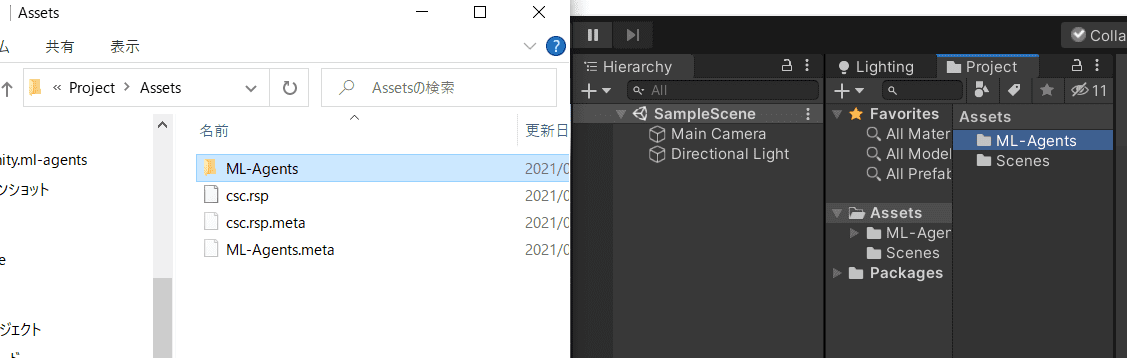
続いて.\ml-agents\Project\Assets\ML-AgentsをプロジェクトのAssetsに置きます。
オブジェクトを配置する
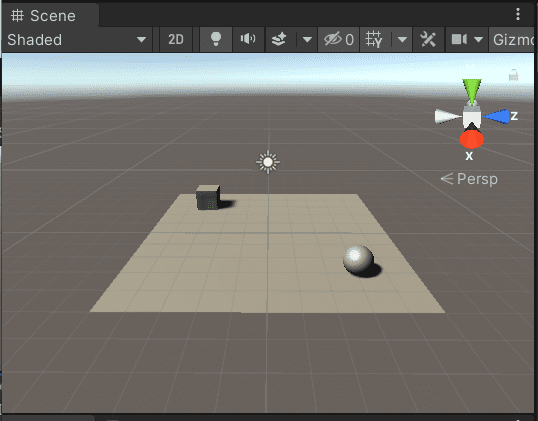
こんな感じになるようフロア(Plane)とエージェント(Sphere)、ターゲット(Cube)を配置します。 メニューの「GameObjects」→「3D Object」からそれぞれ選んで配置して下さい。
| Name | 3D Object | Scale(x, y, z) | Position (x, y, z) | |
|---|---|---|---|---|
| フロア | Floor | Plane | (1, 1, 1) | (0, 0, 0) |
| エージェント | BallAgent | Sphere | (1, 1, 1) | (3, 0.5, 3) |
| ターゲット | Target | Cube | (1, 1, 1) | (-3, 0.5, -3) |
Rotationは全て(0,0,0)です。 y軸を0.5上にずらすと丁度フロアの上にオブジェクトが乗っかります(Scale(1, 1, 1)のとき)。
Unityではカメラの奥行きがz軸になるようです。
カメラはMain Cameraを選択してCtrl+Shift+Fを押すとSceneと同じ画角になります。このショートカットは便利。
色をつけてみる
このままだと渋すぎるので、色付けてやる気が出る感じにしましょう。
AssetsでMaterialsフォルダを作成して、Materialを追加します。
「右クリック」→「Create」→「Material」で新しくマテリアルが追加できます。
「Albedo」で色を作れます。
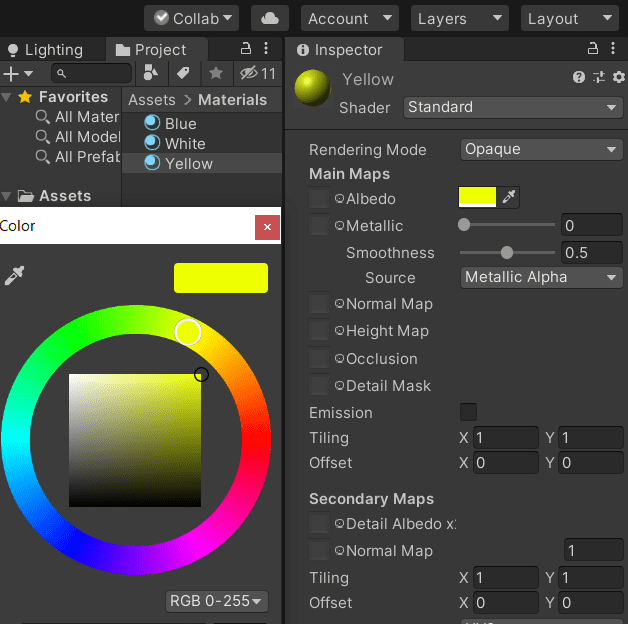
作ったMaterialをドラッグしてSceneのオブジェクトにドロップすると付けることができます。
初回はMaterialを付けても色が変わらず茶色いままだと思います。 メニューバーから「Window」→「Rendering」→「LightingSettings」を開く。一番下の「Auto Generate」にチェックすると色実のある世界になります。 詳しくはこちら。
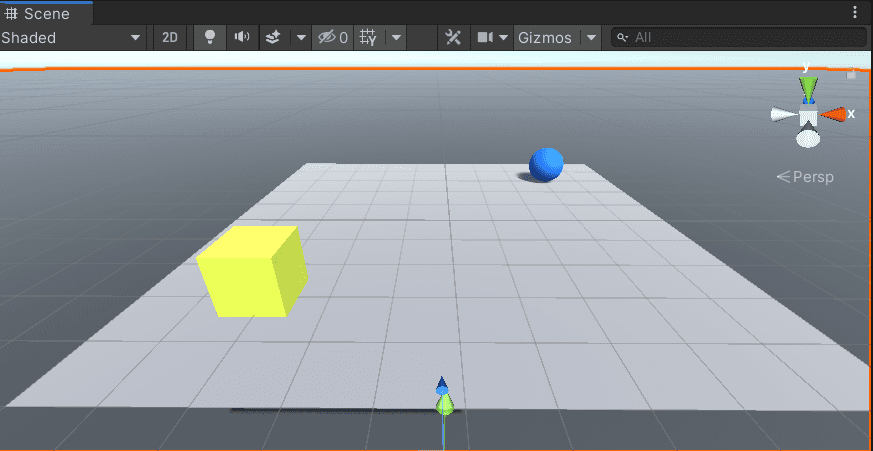
Unityの2019.xからこの設定が必要になったそうです。
エージェントに物理特性をつける
エージェントに物理特性を与えるRigidbodyコンポーネントを追加します。
BallAgentを選択してInspecterの下のほうにある「Add Component」から「Rigitbody」を探して追加します。
これで重力の影響を受けたりスクリプトから力を与えられるようになりました。
プロパティはRigidbody - Unity Documentationを参照してください。
▼以上までの設定のInspecterです。
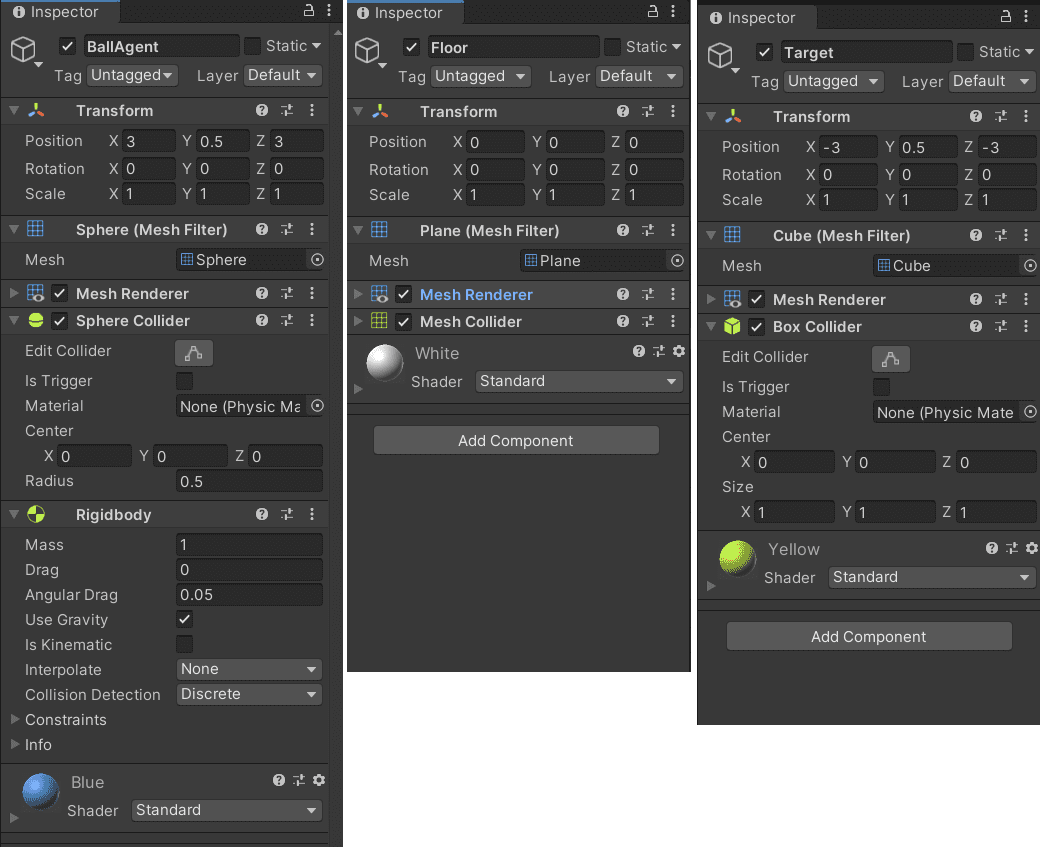
トレーニングエリアのグループにする
作成したエージェントとフロアとターゲットをトレーニングエリアとしてグループにします。
- Hierarchy で右クリックして「Create Empty」で空のGameObjectを新しく作ります。名前を
TrainingAreaとする。 - トレーニングエリアのTransform は Position (0,0,0), Rotation (0,0,0), Scale (1,1,1)としておく。
- エージェントとフロアとターゲットをトレーニングエリアにドラッグ&ドロップしてグループにします。
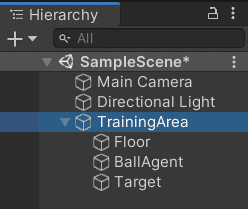
こうすることでエージェントらがトレーニングエリアのローカル座標で動くので、移動したり並列に学習しやすくなります。
エージェントを実装する
遂にエージェントにスクリプトを書いて実装するフェーズになりました!
まず、スクリプトの追加します。
エージェントのinspecterで「Add Component」をクリックして「New Script」を選択する。名前を「RollerAgent」とします。
プロジェクトのAsset/RollerAgent.csとファイルが出来るのでフォルダを作ってAsset/Scripts/RollerAgent.csと整理しました。
エクスプローラーから探して直接編集するか、Inspecterから「Edit Script」で編集する。
▼最初のスクリプト。クラス名が名付けたRollerAgentになってます。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class RollerAgent : MonoBehaviour
{
// Start is called before the first frame update
void Start()
{
}
// Update is called once per frame
void Update()
{
}
}
これ以降は順番に機能を追加していき、最後に全文載せます。
ML-Agentsのパッケージを追加します。
基底クラスをMonoBehaviour から Agentに変更する.
関数をstart()残してupdate()を削除します。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
public class RollerAgent : Agent
{
// Start is called before the first frame update
void Start()
{
}
}
ここまでがどのML-Agentsのプロジェクトも同様な前準備です。 (基底クラスは継承元の親クラスやスーパークラスとも言います。)
続いて、エージェントがターゲットに向かって転がっていく強化学習のロジックを作っていきます。 具体的には、基底のAgentクラスから3つのメソッドを拡張する必要があります。
OnEpisodeBegin()CollectObservations(VectorSensor sensor)OnActionReceived(ActionBuffers actionBuffers)以下の専用サブセクションで、これらのそれぞれについて詳しく説明します。
学習のロジック
メソッドの前に学習のロジックを整理しておきます。
1つのエピソードは次の手順で実行します。
- Episode Begin エージェントの初期化
- エージェントがフロアから落下していた場合は位置をリセットする。
- ターゲットをランダムに配置する。
- Observation 環境の観察
- エージェントの位置と速度、ターゲットの位置を取得する(位置がx, y, zで速度x, z軸方向の8項目を得る)。
- Action 行動を起こす
- 観察を元に力を加える方向(x, z軸)を決める。
- Reward 報酬を割り当てる
- ターゲットに到達したとき報酬を与える。
- End Eposode エージェントのリセット
- ターゲットに到達するか、フロアから落下したときにエピソードを終了する。
今回は報酬がターゲットに到達したときのみ与えられます。 フロアが小さいので、エージェントがランダムに動いてもターゲットにたまたま到達することが期待でき学習が進みます。
学習するモデルは入力が8項目、出力が2項目となっています。 今回は強化学習のアルゴリズムに「PPO」(Proximal Policy Optimization)を利用します。 モデルは別途yamlで設定するため、エージェントのスクリプトは別のモデルでも変更なしで利用出来ます。
エージェントの初期化とリセット
start()が学習を始めたとき、OnEpisodeBegin()がエピソードの初期設定です。
public class RollerAgent : Agent
{
Rigidbody rBody;
void Start () {
rBody = GetComponent<Rigidbody>();
}
public Transform Target;
public override void OnEpisodeBegin()
{
// エージェントがフロアからはみ出て落下しているとき
if (this.transform.localPosition.y < 0)
{
// エージェントの位置と速度を初期化する
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3( 0, 0.5f, 0);
}
// ターゲットをランダムな位置に配置する
Target.localPosition = new Vector3(Random.value * 8 - 4,
0.5f,
Random.value * 8 - 4);
}
}
Agent.OnEpisodeBegin()ではこの2つの処理を実装しています。
- エージェントがフロアから落下していた場合は位置をリセットする。
- ターゲットをランダムに配置する。
InspecterでTargeを選択しておきます。
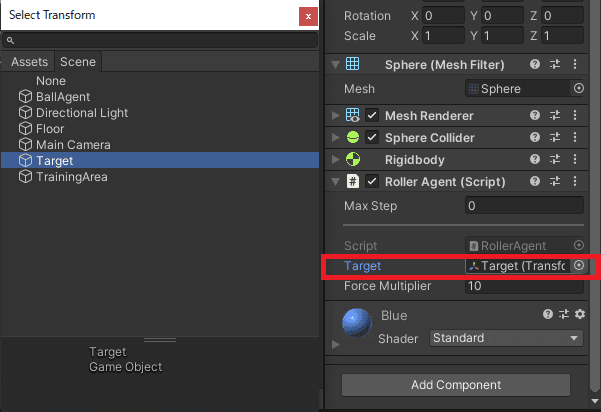
環境を観察する
学習の入力にあたるAgent.CollectObservations(VectorSensor sensor)を実装します。
ここで得た情報を元にモデルは次の行動を決めます。 目的には何が必要かを考え正しい情報を収集しなければなりません。
引数のsensorに入力として利用する値を加えます。
public override void CollectObservations(VectorSensor sensor)
{
// ターゲットとエージェントの位置
sensor.AddObservation(Target.localPosition);
sensor.AddObservation(this.transform.localPosition);
// エージェントの速度
sensor.AddObservation(rBody.velocity.x);
sensor.AddObservation(rBody.velocity.z);
}
到達するためにターゲットとエージェントの位置情報が必要です。 また、エージェントの速度も観測してフロアから落ちてしまうことを防ぎます。 ターゲットとエージェントの位置が(x, y, z)の各3つ、エージェントのx, z軸方向の速度と合計8項目を観測します。
ターゲットの位置を使わず、エージェントからターゲットへの方向を利用するのも面白そう。
行動を起こして報酬を割り当てる
最後に行動を起こして報酬を割り当てるAgent.OnActionReceived()を実装します。
引数のactionBuffersがモデルが決定した行動です。
これをエージェントに与えて操作します。
また、この関数にエピソードを終了する判定も加えています。
// 加える力の係数
public float forceMultiplier = 10;
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// 行動, size = 2
// x, z軸方向に力を加える
Vector3 controlSignal = Vector3.zero;
controlSignal.x = actionBuffers.ContinuousActions[0];
controlSignal.z = actionBuffers.ContinuousActions[1];
rBody.AddForce(controlSignal * forceMultiplier);
// 報酬
// ターゲットとの距離を測る
float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition);
// ターゲットに到達したとき
if (distanceToTarget < 1.42f)
{
// 報酬を受け取りエピソードを終了する
SetReward(1.0f);
EndEpisode();
}
// フロアから落下したとき
else if (this.transform.localPosition.y < 0)
{
// エピソードを終了する
EndEpisode();
}
}
テストの環境
人間が自らエージェントを操作することも可能です。
キー操作を引数にとるAgent.Heuristic(in ActionBuffers actionsOut)を実装します。
public override void Heuristic(in ActionBuffers actionsOut)
{
var continuousActionsOut = actionsOut.ContinuousActions;
continuousActionsOut[0] = Input.GetAxis("Horizontal");
continuousActionsOut[1] = Input.GetAxis("Vertical");
}
スペースキーを取りたい場合はこうactionsOut[1] = Input.GetKey(KeyCode.Space) ? 1.0f : 0.0f;
RollerAgent.cs
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
public class RollerAgent : Agent
{
Rigidbody rBody;
void Start()
{
rBody = GetComponent<Rigidbody>();
}
public Transform Target;
public override void OnEpisodeBegin()
{
// エージェントがフロアからはみ出て落下しているとき
if (this.transform.localPosition.y < 0)
{
// エージェントの位置と速度を初期化する
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3(0, 0.5f, 0);
}
// ターゲットをランダムな位置に配置する
Target.localPosition = new Vector3(Random.value * 8 - 4,
0.5f,
Random.value * 8 - 4);
}
public override void CollectObservations(VectorSensor sensor)
{
// ターゲットとエージェントの位置
sensor.AddObservation(Target.localPosition);
sensor.AddObservation(this.transform.localPosition);
// エージェントの速度
sensor.AddObservation(rBody.velocity.x);
sensor.AddObservation(rBody.velocity.z);
}
// 加える力の係数
public float forceMultiplier = 10;
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// 行動, size = 2
// x, z軸方向に力を加える
Vector3 controlSignal = Vector3.zero;
controlSignal.x = actionBuffers.ContinuousActions[0];
controlSignal.z = actionBuffers.ContinuousActions[1];
rBody.AddForce(controlSignal * forceMultiplier);
// 報酬
// ターゲットとの距離を測る
float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition);
// ターゲットに到達したとき
if (distanceToTarget < 1.42f)
{
// 報酬を受け取りエピソードを終了する
SetReward(1.0f);
EndEpisode();
}
// フロアから落下したとき
else if (this.transform.localPosition.y < 0)
{
// エピソードを終了する
EndEpisode();
}
}
public override void Heuristic(in ActionBuffers actionsOut)
{
var continuousActionsOut = actionsOut.ContinuousActions;
continuousActionsOut[0] = Input.GetAxis("Horizontal");
continuousActionsOut[1] = Input.GetAxis("Vertical");
}
}
振る舞いと行動決定頻度
エージェントのInspecterの「Add Component」からBehavior ParametersとDecision Requesterを追加します。
Behavior Parametersはエージェントの振る舞いを決めるパラメータで、観測(入力)の数やモデルを設定する。
Space Size: 観測(入力)の数。今回はターゲットとエージェントの位置が(x, y, z)の各3つ、エージェントのx, z軸方向の速度と合計8項目を観測します。Modelはニューラルネットワークのモデルを指定する項目。 学習済のモデルを指定してPlayするとそのモデルでエージェントを動かすことができる。
Decision Requesterは定期的にエージェントの決定を要求するコンポーネントです。
DecisionPeriodは定期的に決定を要求する頻度。
基本的に1ステップは0.02秒毎です。DecisionPeriodが5の場合、エージェントは5ステップごと(秒毎)に決定を要求します。
▼ここまでのエージェントのInsptector。長いので折り返してます。
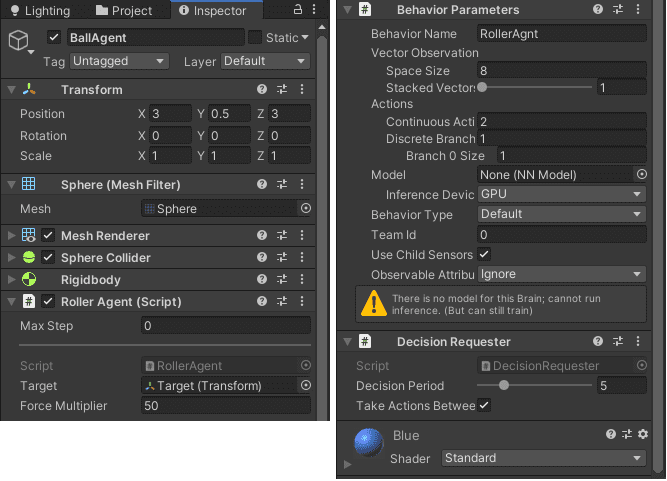
モデルのハイパーパラメータ
いよいよPythonで学習していきます。
まずはモデルのハイパーパラメータを決めます。
新しくNewLearningEnvironment\config\RollerBall.yamlを作成して設定を書きます。
behaviors:
RollerBall:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 500000
time_horizon: 64
summary_freq: 10000
ハイパーパラメータの詳細はthe training configuration file documentationにあります。
疲れたので詳しくパラメータについてはまた別の記事で書く。
学習はmlagents-learn 設定.yaml --run-id=実行IDでUnityの実行を待ち受けます。
# Anaconda
> conda activate mlagents
> cd C:\unity\NewLearningEnvironment
> mlagents-learn .\config\RollerBall.yaml --run-id=RollerBall
# 学習の続きを実行する場合
> mlagents-learn .\config\RollerBall.yaml --run-id=RollerBall --resume
# 学習を破棄して新しく実行する場合
> mlagents-learn .\config\RollerBall.yaml --run-id=RollerBall --force
私の環境はAnacondaを利用していて、mlagentsという名前でPythonの環境をつくってます。
学習の続きを実行する場合はオプション--resumeをつけて実行します。
また、学習を破棄して新しく実行する場合はオプション--forceをつけて実行します。
学習を実行したらUnityのPlayボタンを押して学習をスタートさせます。
以上で学習できる。
学習を止める際は、UnityのPlayボタンをクリックするか、ターミナルでCtrl+Cで止める。
どちらもそれまでに学習したモデルが保存されます。
NewLearningEnvironment\results\RollerBall\RollerAgnt.onnxに保存されてました。
エージェントを学習したモデルで動かす
AssetsにNewLearningEnvironment\results\RollerBall\RollerAgnt.onnxをドラッグ&ドロップします。
エージェントのBehavior ParametersのModelに先ほど置いたモデルをドラッグ&ドロップして紐づけました。
Playボタンをクリックするとそのモデルで実行できます。
参考書
UnityもML-Agentsもわからなかったので参考書を買いました。 日本語のUnity + ML-Agentsの書籍はこれだけです。
Unityではじめる機械学習・強化学習 Unity ML-Agents実践ゲームプログラミング
この本の