重要なクラスタリングの手法のひとつがk-meansです。 Pythonでクラスタリング分析をするため、顧客情報にk-meansを適用するまでの流れを記録します。
k-meansとは?
データを与えられたk個のクラスタに分類するアルゴリズムです。
クラスタリングする手順は一般的に以下の通り。
- データをランダムにk個のクラスターに割り振る。
- クラスターの中心を求める。
- 各クラスタの中心との距離を求め、一番近い中心のクラスタに割り振ります。
- 2と3を繰り返してクラスターが変動しなくなれば終了。
step2とstep3のイメージ
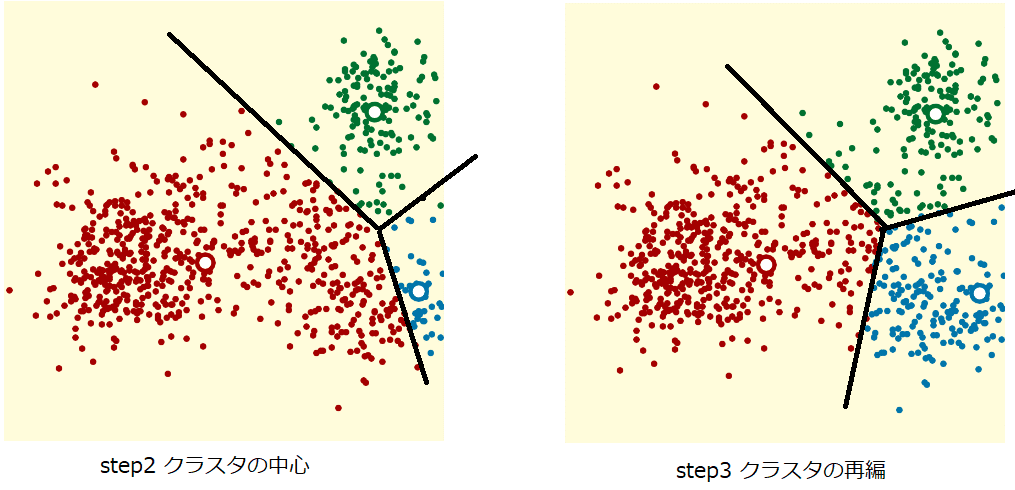
step2からstep3へクラスタが更新している。
下記の記事で、JavaScriptでクラスタリングの過程を可視化しています。 良ければご覧下さい。
データについて
Kaggleのデータセットからデータを拝借しました。 この中のMall Customer Segmentation Dataを利用します。
このデータセットは、マーケットバスケット分析とも呼ばれる、顧客セグメンテーションの概念を学習する目的で公開されています。 UdemyのMachine Learning AZコース での学習用らしいです。
今回はUdemyは見ないように、自分なりに解析をしてみます。
データの準備
Mall_Customers.csvと名前のCSVデータをダウンロードしました。 200行×5列の小さめなデータです。
各カラムについて
| Column | Description |
|---|---|
| CustomerID | 整数のユニークなID |
| Gender | 顧客の性別 |
| Age | 顧客の年齢 |
| Annual Income (k$) | 顧客の年収 |
| Spending Score (1-100) | 顧客の行動と支出から割り当てられたスコア |
これを元にクラスタリングしていきます。
データの解析
ここからPythonで解析を進めます。
環境とインストール
- Python 3.7
- Windows 10
- Jupyter Notebook on VSCode
VSCodeの拡張機能のJupyterを利用しています。 ※別途、pipでjupyter notebookをインストールする必要がある。
モジュールは以下を使っています。
jupyter==1.0.0
notebook==5.7.6
numpy==1.16.2
pandas==0.24.2
seaborn==0.9.0
sklearn==0.0下のコマンドでインストールできます。バージョンが気になる場合は、上のバージョンを使ってみてください。
$ python -m pip install --upgrade pip
$ python -m pip install jupyter notebook numpy pandas seaborn sklearn
データの読み込み
コーディングしていきます。
#%%
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.cluster import KMeans
import os
path = "{このCSVのパス}\\Mall_Customers.csv"
# CSVファイルの読み込み。
df = pd.read_csv(path, encoding="UTF-8")
# 前方10件を表示します。
df.head()
VSCodeのJupyterだと#%%でセルを区切ります。
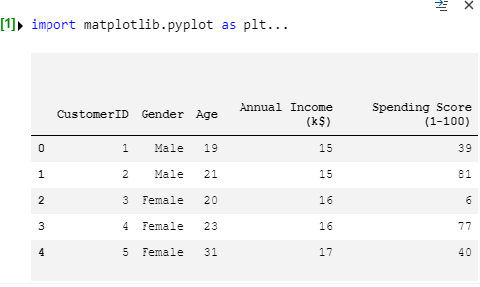
いい感じに出力を見ることができます。
pd.read_csv()はカラム名も勝手に読んでくれます。
性別がMaleとFemaleになっていることが分りました。
データを眺めてみる
統計的にデータを眺めてみます。
#%%
_df = df
# 文字列を数値に置き換える
_df = _df.replace("Male", 0)
_df = _df.replace("Female", 1)
# データの雰囲気をつかむ
_df.describe()
df.describe()で基本的な統計量を簡単に見ることができます。
その前に性別の文字列は計算できないので、数値に置き換えています。
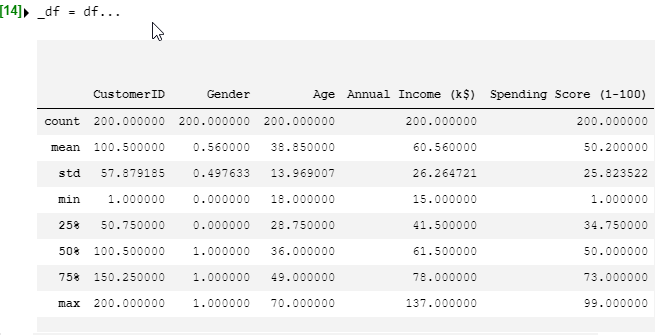
全て200件あり欠損値はなさそうです。
平均、標準偏差、最大・最小値、4分区間と各列の特徴を表す統計値が簡単に出ました。 例えば、
- 男性:女性 = 44 : 56
- 平均年収は60.56k$
- Spending Scoreは25%,50%,75%で均等な感じがする。 と目星が着きます。
グラフにしてみる
もう少しわかり易くグラフにしてみます。
#%%
sns.distplot(df['Spending Score (1-100)'])
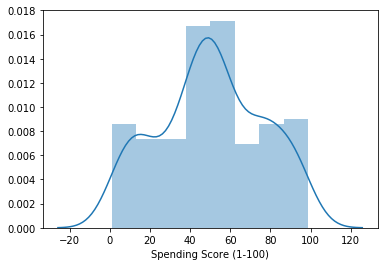
sns.distplot()で度数分布(ヒストグラム)を描きました。
近似曲線も出てくるようです。
一様分布かと思っていたら、歪な正規分布でした。
他の列と比較してみる
sns.joinplot()で2次元の散布図を描けます。
#%%
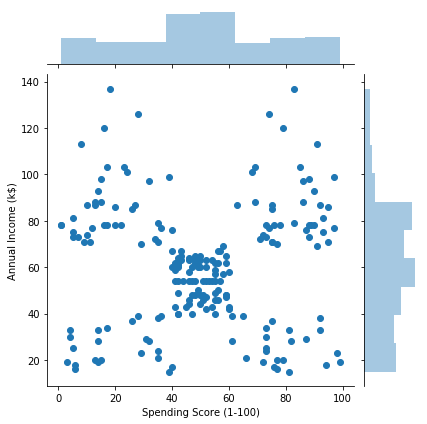
sns.jointplot(x='Spending Score (1-100)', y='Annual Income (k$)', data=df)
#%%
sns.jointplot(x='Spending Score (1-100)', y='Age', data=df)
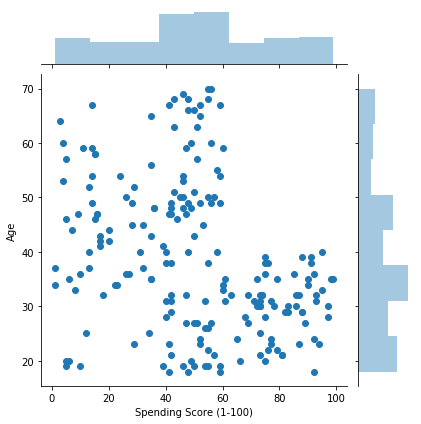
思った以上に個性的なデータですね。
Spending Score (1-100) vs Annual Income (k$)をk-meansでデータを5つに別れるのが狙いでしょうか?
男女の違いを検討してみる。
df[df["Gender"] == "Male"]とすると男性だけのデータを扱えます。逆も同様。
#%%
# 男女のデータ
man = df[df["Gender"] == "Male"]
woman = df[df["Gender"] == "Female"]
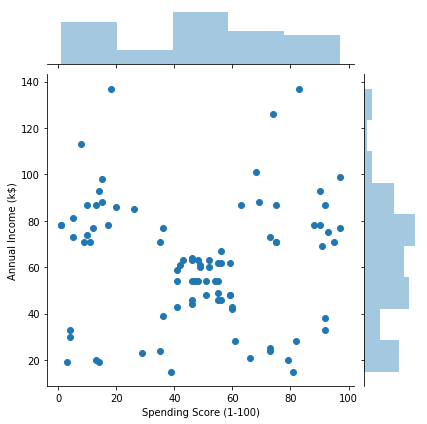
sns.jointplot(x='Spending Score (1-100)', y='Annual Income (k$)', data=man)
sns.jointplot(x='Spending Score (1-100)', y='Annual Income (k$)', data=woman)
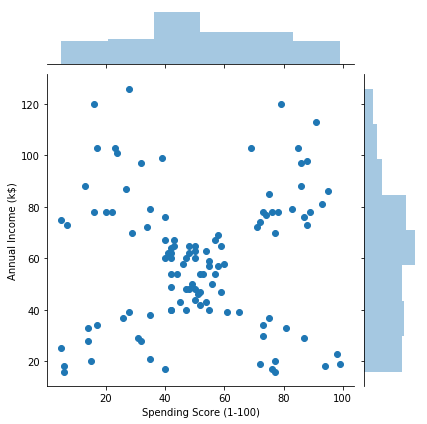
男女の違いは少なそうです。
k-meansでクラスタリング
長くなりましたがk-meansを使ってクラスタリングしてみます。
from sklearn.cluster import KMeans
先にインポートしたskleanのKMeansを使います。
文字は距離を計算出来ないため、数値に変換します。
クラスタ数を渡して表示する関数を作成しました。
また、sns.relplot()で2次元の散布図として、col="Gender"とすることで性別の比較出来るグラフとしています。
#%%
def clustering(k, df):
# 文字を数値に変換
_df = df.replace("Male", 0)
_df = _df.replace("Female", 1)
# k-means
pred = KMeans(n_clusters=k).fit_predict(_df)
_df['cluster_id'] = pred
# 結果を表示
sns.relplot(x='Spending Score (1-100)',
y='Annual Income (k$)', data=_df,
col="Gender", hue='cluster_id')
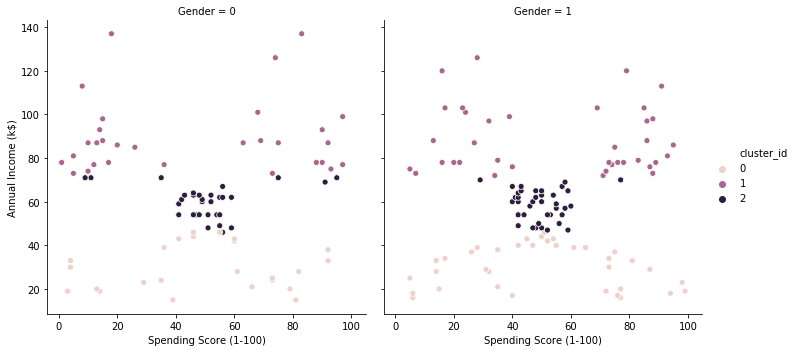
k=3のとき
clustering(3, df)
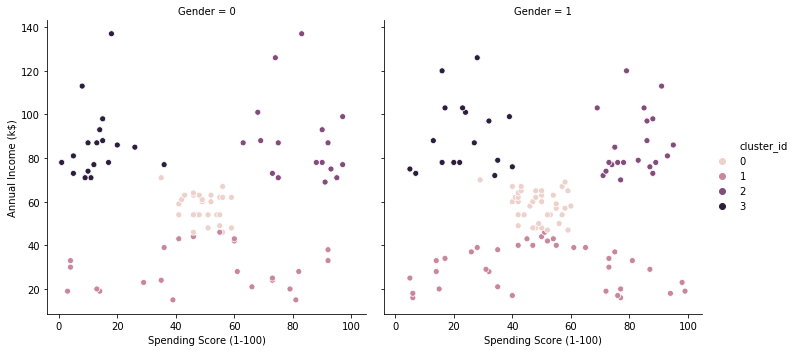
k=4のとき
clustering(4, df)
k=5のとき
clustering(5, df)
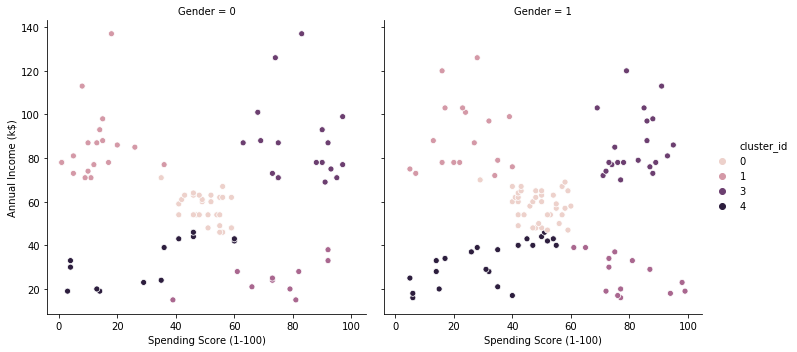
それぞれ、綺麗にグループ化出来てのではないでしょうか? 本当はこの結果かから有益な情報を見いだせたら良いのですが、今回は可視化出来たところで終えます。